This post is not directly about MicroServices. If that is why you are reading it, might as well stop now. Apparently, we are still waiting as for the definition to be finally ratified. The definition, as it stands now, is blurry - Martin Fowler admits. This post is about Actors - the cloud ones - you know. After finishing reading it, I hope I have made it effortlessly clear how Reactive Cloud Actors are the real MicroServices, rather than albeit light RESTful Imperative MicroServices.
Watching Fred George delivering an excellent talk on High-Performance Bus inspired me to start working on the actors. I am still working on a final article on the subject but this post is basically a primer on that - as well as announcement of BeeHive mini-framework. The next section on actors is taken from that article which covers the essential theoretical background. Before we start, let's make it clear that the term Reactive is not used in the context of Reactive Extensions (Rx) or Frameworks, only in contrast to imperative (RPC-based) actors. Also RPC-based is not used in contrast to RESTful, but it simply means a system which relies on command and query messages rather than events.
UPDATE: The article is now published on infoq here.
Actors
Carl Hewitt, along with Peter Bishop and Richard Steiger, published an article back in 1973 that proposed a formalism that identified a single class of objects, i.e. Actors, as the building blocks of systems designed to implement Artificial Intelligence algorithms.
According to Hewitt an actor, in response to a message, can:
- Send a finite number of messages to other actors
- create a finite number of other actors
- decide on the behaviour to be used for the next message it receives
Any combination of these actions can occur concurrently and in response to messages arriving in any order - as such, there is no constraint with regard to ordering and an actor implementation must be able to handle messages arriving out of band. However, I believe it is best to separate these responsibilities as below.
Processor Actor
In a later description of the Actor Model, first constraint is re-defined as "send a finite number of messages to the address of other actors". Addressing is an integral part of the model that decouples actors and limits the knowledge of actors from each other to mere a token (i.e. address). Familiar implementation of addressing includes Web Services endpoints, Publish/Subscribe queue endpoints and email addresses. Actors that respond to a message by using the first constraint can be called Processor Actors.
Factory Actor
Second constraint makes actors capable of creating other actors that we conveniently call Factory Actors. Factory actors are important elements of a message-driven system where an actor is consuming from a message queue and create handlers based on the message type. Factory actors control the lifetime of the actors they create and have a deeper knowledge of the actors they create - compared to processor actors knowing mere an address. It is useful to separate factory actors from processing ones - in line with the single responsibility principle.
Stateful Actor
Third constraint is the Stateful Actor. Actors capable of the third constraint have a memory that allows them to react differently on subsequent messages. Such actors can be subject to a myriad of side-effects. Firstly, when we talk about "subsequent messages" we inherently assume an ordering while as we said, there is no constraint with regard to ordering: an out of band message arrival can lead to complications. Secondly, all aspects of CAP applies to this memory making a consistent yet highly available and partition tolerant impossible to achieve. In short, it is best to avoid stateful actors.
Modelling a Processor Actor
 |
| "Please open your eyes, Try to realise, I found out today we're going wrong, We're going wrong" - Cream |
[Mind you there is only a glimpse of Ginger Baker visible while the song is heavily reliant on Ginger's drumming. And yeah, this goes back to a time when Eric played Gibson and not his signature Strat]
This is where most of us can go wrong. We do that, sometimes for 4 years - without realising it. This is by no means a reference to a certain project [... cough ... Orleans ... cough] that has been brewing (Strange Brew pun intended) for 4 years and coming up with an imperative, RPC-based, RESTfully coupled Micro-APIs. We know it, doing simple is hard - and we go wrong, i.e. we do the opposite: build really complex frameworks.
I was chatting away on twitter with a few friends and I was saying "if you need a full-blown and complex framework to do actors, you are probably doing it wrong". All you need is a few interfaces, and some helpers doing the boilerplate stuff. This stuff ain't no rocket science, let's not turn it into.
The essence of the Reactive Cloud Actor is the interface below (part of BeeHive mini-framework introduced below):
/// <summary>
/// Processes an event.
///
/// Queue name containing the messages that the actor can process messages of.
/// It can be in the format of [queueName] or [topicName]-[subscriptionName]
/// </summary>
public interface IProcessorActor : IDisposable
{
/// <summary>
/// Asynchrnous processing of the message
/// </summary>
/// <param name="evnt">Event to process</param>
/// <returns>Typically contains 0-1 messages. Exceptionally more than 1</returns>
Task<IEnumerable<Event>> ProcessAsync(Event evnt);
}
Yes, that is all. All of your business can be captured by the universal method above. Don't you believe that? Just have a look a non-trivial eCommerce example implemented using this single method.
So why Reactive (Event-based) and not Imperative (RPC-based)? Because in a reactive actor system, each actor only knows about its own Step and what itself does and has no clue about the next steps or the rest of the system - i.e. actors are decoupled leading to independence which facilitates actor Application Lifecycle Management and DevOps deployment.

So let's bring an example: fraud check of an order.
Imperative
PaymentActor, after a successful payment for an order, calls the FraudCheckActor. FraudCheckActor calls external fraud check systems. After identifying a fraud, it calls CancelOrderActor to cancel the order. So as you can see, PaymentActor knows about and depends on FraudCheckActor. In the same way, FraudCheckActor depends on CancelOrderActor. They are coupled.
Reactive
PaymentActor, upon successful payment, raises PaymentAuthorised event. FraudCheckActor is one of its subscribers and after receiving this event checks for fraud and if one detected, raises FraudDetected event. CancelOrderActor subscribers to some events, including FraudDetected upon receiving which it cancels the order. None of these actors know about the other. They are decoupled.
So which one is better? By the way, none of this is new - we have been doing it for years. But it is important to identify why we should avoid the first and not to "go wrong".
Reactive Cloud Actors proposal
After categorising the actors, here I propose the following constraints for Reactive Cloud Actors:
- A reactive system that communicates by sending events
- Events are defined as a time-stamped, immutable, unique and eternally-true piece of information
- Events have types
- Events are stored in a Highly-Available cloud storage queues allowing topics
- Queues must support delaying
- Processor Actors react to receiving a single and then do some processing and then send back usually one (sometimes zero and rarely more than one) event
- Processor Actors have type - implemented as a class
- Processing should involve minimal number of steps, almost always a single step
- Processing of the events are designed to be Idempotent
- Each Processor Actor can receive one or more event types - all of which defined by Actor Description
- Factory Actors responsible for managing the lifetime of processor actors
- Actors are deployed to cloud nodes. Each node contains one Factory Actor and can create one or more Processor Actor depending on its configuration. Grouping of actors depends on cost vs. ease of deployment.
- In addition to events, there are other Basic Data Structures that contain state and are stored in Highly-Available cloud storage (See below on Basic Data Structures)
- There are no Stateful Actors. All state is managed by the Basic Data Structures and events.
- This forms an evolvable web of events which can define flexible workflows
Breaking down all the processes into single steps is very important. A Highly-Available yet Eventually-Consistent system can handle delays but cannot easily bind multiple steps into a single transaction.
So how can we implement this? Is this gonna work?
 BeeHive is a vendor-agnostic Reactive Actor mini-framework I have been working over the last three months. It is implemented in C# but frankly could be done in any language supporting Asynchronous programming (promises) such as Java or node.
BeeHive is a vendor-agnostic Reactive Actor mini-framework I have been working over the last three months. It is implemented in C# but frankly could be done in any language supporting Asynchronous programming (promises) such as Java or node.
So how can we implement this? Is this gonna work?
Introducing BeeHive
BeeHive is a vendor-agnostic Reactive Actor mini-framework I have been working over the last three months. It is implemented in C# but frankly could be done in any language supporting Asynchronous programming (promises) such as Java or node.
The cloud implementation has been only implemented for Azure but implementing another cloud vendor is basically implementing 4-5 interfaces. It also comes with an In-Memory implementation too which is only targeted at implementing demos. This framework is not meant to be used as an in-process actor framework.
It implements Prismo eCommerce example which is an imaginary eCommerce system and has been implemented for both In-Memory and Azure. This example is non-trivial has some tricky scenarios that have to implement Scatter-Gather sagas. There is also a Boomerang pattern event that turns a multi-step process into regurgitating an event a few times until all steps are done (this requires another post).
An event is model as:
It implements Prismo eCommerce example which is an imaginary eCommerce system and has been implemented for both In-Memory and Azure. This example is non-trivial has some tricky scenarios that have to implement Scatter-Gather sagas. There is also a Boomerang pattern event that turns a multi-step process into regurgitating an event a few times until all steps are done (this requires another post).
An event is model as:
[Serializable]
public sealed class Event : ICloneable
{
public static readonly Event Empty = new Event();
public Event(object body)
: this()
{
...
}
public Event()
{
...
}
/// <summary>
/// Mrks when the event happened. Normally a UTC datetime.
/// </summary>
public DateTimeOffset Timestamp { get; set; }
/// <summary>
/// Normally a GUID
/// </summary>
public string Id { get; private set; }
/// <summary>
/// Optional URL to the body of the message if Body can be retrieved
/// from this URL
/// </summary>
public string Url { get; set; }
/// <summary>
/// Content-Type of the Body. Usually a Mime-Type
/// Typically body is a serialised JSON and content type is application/[.NET Type]+json
/// </summary>
public string ContentType { get; set; }
/// <summary>
/// String content of the body.
/// Typically a serialised JSON
/// </summary>
public string Body { get; set; }
/// <summary>
/// Type of the event. This must be set at the time of creation of event before PushAsync
/// </summary>
public string EventType { get; set; }
/// <summary>
/// Underlying queue message (e.g. BrokeredMessage in case of Azure)
/// </summary>
public object UnderlyingMessage { get; set; }
/// <summary>
/// This MUST be set by the Queue Operator upon Creation of message usually in NextAsync!!
/// </summary>
public string QueueName { get; set; }
public T GetBody<T>()
{
...
}
public object Clone()
{
...
}
}
As can be seen, Body has been defined as a string since BeeHive uses JSON serialisation. This can be made flexible but in reality events should normally contain small amount of data and mainly basic data types such as GUID, integer, string, boolean and DateTime. Any binary data should be stored in Azure Blob Storage or S3 and then path referenced here.
BeeHive Basic Data Structures
This is a work-in-progress but nearly done part of the BeeHive to define a minimal set of Basic Data Structures (and their stores) to cover all required data needs of Reactive Actors. These structures are defined as interfaces that can be implemented for different cloud platforms. This list as it stands now:- Topic-based and simple Queues
- Key-Values
- Collections
- Keyed Lists
- Counters
Some of these data structures hold entities within the system which should implement a simple interface:
public interface IHaveIdentity
{
Guid Id { get; }
}
Optionally, entities could be Concurrency-Aware for updates and deletes in which case they will implement an additional interface:
public interface IConcurrencyAware
{
DateTimeOffset? LastModofied { get; }
string ETag { get; }
}
Prismo eCommerce sample
Prismo eCommerce is an imaginary eCommerce company that receives orders and processes them. The order taking relies on an eventually consistent (and delayed) read model of the inventory hence orders can be accepted for which items are out of stock. Process waits until all items are in stock or if out of stock, they arrive back in stock until it sends them to fulfilment.
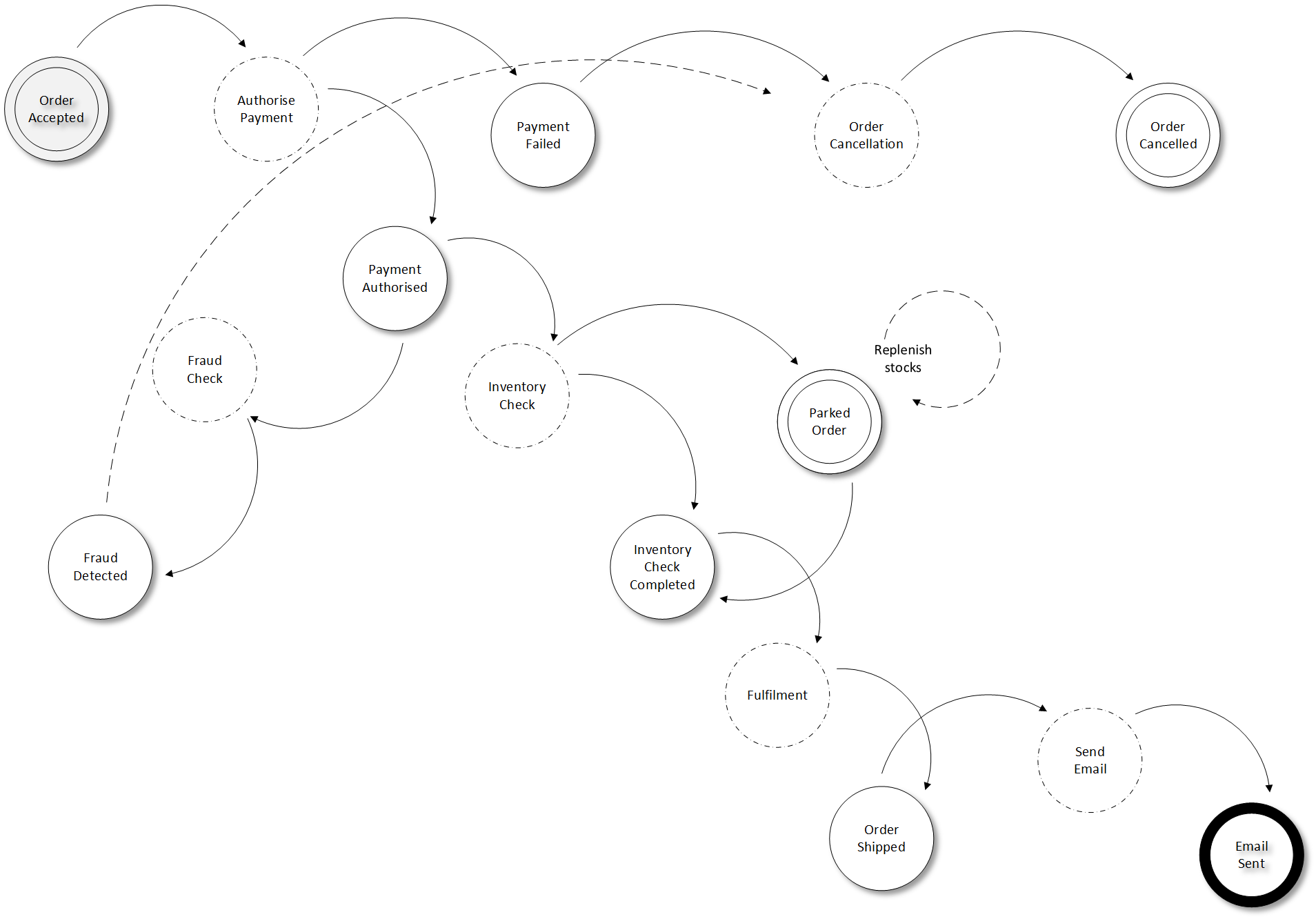 |
| Prismo eCommerce states (solid), transitions (arrows) and processes (dashed) |
This sample has been implemented both In-Memory and for Windows Azure. In both cases, the tracing can be used to see what is happening outside. In this sample all actors are configured to run in a single worker role, although they can each run in their own roles. I might provide a UI to show the status of each order as they go through statuses.
Conclusion
Reactive Cloud Actors are the way to implement decoupled MicroServices. By individualising actor definitions (Processor Actor and Factory Actor) and avoiding Stateful Actors, we can build resilient and Highly Available cloud based systems. Such systems will comprise a evolvable webs of events which each web defines a business capability. I don't know about you but this is how I am going to build my cloud systems.
Watch the space, the article is on its way.
Cool article, thanks for posting it.
ReplyDeleteI was just looking at your example and isn't there are race condition where 'payment authorized' branches out to the fraud check and inventory check? It looks like the order could go all the way through and ship before the fraud check ever returns, because there's no event emitted for "no fraud" nor an actor that checks for *both* "no fraud" and "inventory in stock".
It would be good to see these divergent and rejoining threads handled, unless I'm missing something with how this should be done with this actor/event model.
Thanks for the feedback. I have not gone into much detail on that but implementing it is easy - and you are right this is missing but I was relying on SLA to be enough. In the C# sample I have not done it but basically 1) an actor listens to fraud check success 2) then flags the order as checked 3) In one of the steps (fulfilment) we add a gate: if no flags, it adds an increasing delay to the message and send back to queue.
DeleteIf you are interested in earning cash from your websites or blogs with popup advertisments - you can try one of the biggest companies - Propeller Ads.
ReplyDeleteWhen you purchase another or utilized auto there is just a single individual that is worried about your needs and that is you. Autoankauf Kiel
ReplyDelete